[SQL] ClickHouse 为什么如此之快?
Posted by Akilis on 03 Jul, 2024
Contents
原理
查询流程
列式存储、多级索引,查询时根据层层索引找到remark文件,按offset读取磁盘压缩块Block,解压缩再按行offset提取列值。
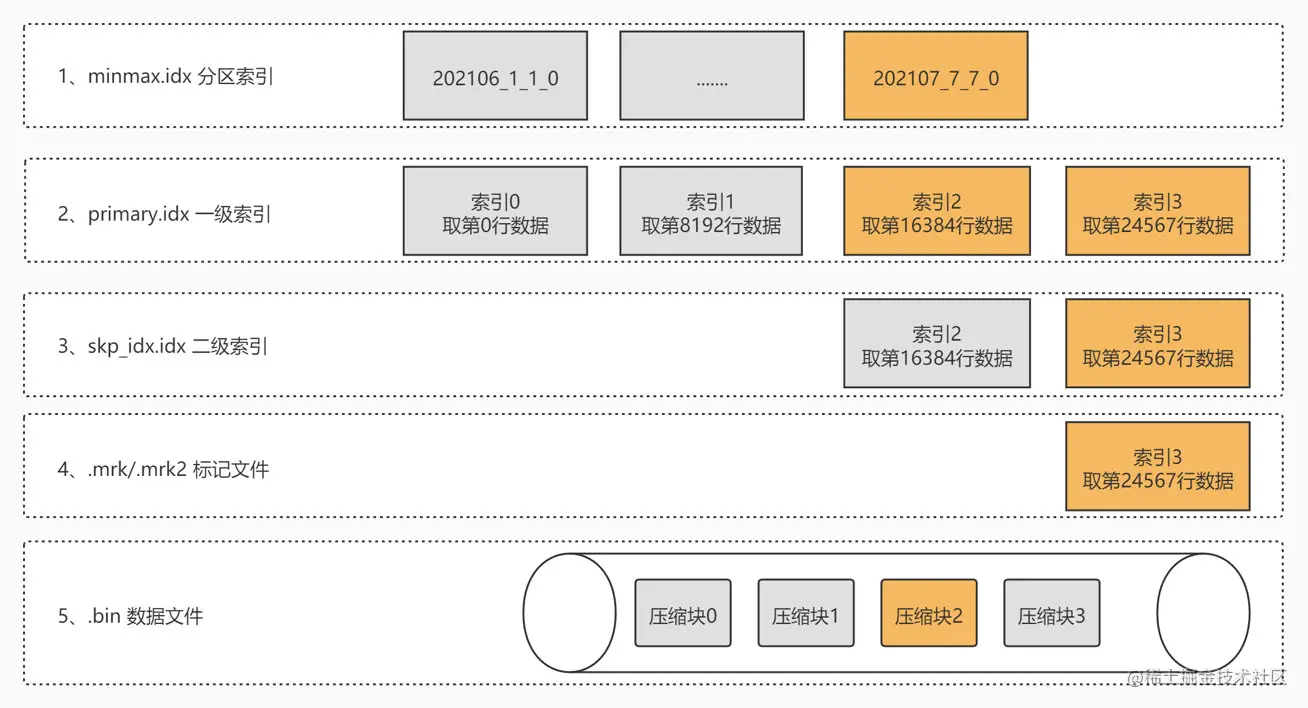
MergeTree
采用LSM存储思想,可基于SkipList数据结构在内存存储k-v索引值对,使用SSTable在磁盘存储数据,异步合并数据part,支持大数据量并发写入,适合大数据数仓构建。
-
DDL
``` ENGINE = ReplicatedMergeTree('/clickhouse/ad_dw_hdd/ks_ad_bi/dm_dsp_tfc_effect_creative_pos_aggr_di/{shard}', '{replica}') PARTITION BY p_date ORDER BY (account_id, campaign_type, product_name, corporation_name, ocpc_action_type) SETTINGS index_granularity = 8192 ``` -
DistributedMergeTree
- 支持Sharding key
- Sharding本身可以直接往server节点写入,或者通过Distributed with Sharding key写入。
- 查询请求 requestor(aka., coordinator) server 发给各server,并行在各server处理local table,聚合中间结果,再最后汇聚到requestor,组合最终结果。
- 使用增强的 Consistent hash 数据结构保存shards信息,添加SHARDS后,也不需要server间迁移数据,通过加权写入new shards, SELECT依然是有效的。
- 对于上百的server cluster,应当使用更复杂的sharding模式。而非简单的为Distributed table指定sharding key.
- 不准确问题
- 因为发送local query到分片执行,再在requestor汇总,因此需要关注函数的精确度,简单的汇总精确度不保证,例如quantile。
- 所以一般函数分类为近似的,或者精确的,加"Exact"后缀,例如uniq/uniqExact。
- 支持Sharding key
- 特点
- 列式存储优势:查询过滤无关列,存储可高度压缩数据,减少I/O;执行查询处理数据时,提高CPU cache命中率,允许使用向量运算 SIMD(单指令多数据).
- LSM 专为大量数据插入而设计。
- 类似pipelining,batch的效果。
- 支持partition key, 过滤数据
- 按照primary key排序,搜索加快
- 支持replication,提高QPS
- 支持sampling,采样过滤
- 与Distributed结合实现scale-out.
- MergeTree 面向 table,如若是Distributed 面向 shard。 {shard}, {replica} 是macros,在config执行时可替换,(zoo_path, replica_name) 保存在例如zookeeper中间件。
优化
Sample
数据集预览、ML采样场景,改写引擎查询,使用子查询抽取表时加 Group By、Sample、LIMIT、Order By rand() 限制数据量,避免失败,提升性能,提升均匀性。
-
近似TopN
settings distributed_group_by_no_merge = 1- 优点:应用范围广,避免失败,提升性能
- 缺点:采样不太均匀。
``` SELECT __time__datetime_1m, _0 FROM ( SELECT 1710864000000 AS __time__datetime_1m, toString(user_id) AS _0 FROM video2019.live_pull_client_log WHERE (datetime_1m >= '2024-03-20 00:00:00') AND (datetime_1m <= '2024-03-20 23:59:59') GROUP BY __time__datetime_1m, _0 ORDER BY __time__datetime_1m ASC, _0 ASC LIMIT 1000 settings distributed_group_by_no_merge = 1 ) GROUP BY __time__datetime_1m, _0 ORDER BY __time__datetime_1m ASC, _0 ASC LIMIT 0, 200 ```
-
SAMPLE X- 优点:避免失败,提升性能,采样较均匀。
- 缺点:应用范围窄,需要表满足SAMPLE BY条件。
``` SELECT 1700582400000 AS __time__p_date, bundle_id AS _0 FROM (select * from ks_radar_plus_public.radar_krn_dwd_load_stat sample 0.01 WHERE p_date >= '20231122' AND p_date <= '20231128') t GROUP BY __time__p_date, _0 ORDER BY __time__p_date, _0 LIMIT 200 OFFSET 0 ```
-
LIMIT Y- 优点:避免失败,提升性能。适合大表(日增行数1E9)。
- 缺点:采样不均匀。
``` -- LIMIT Y: 40+ rows, 1s SELECT 1700582400000 AS __time__p_date, bundle_id AS _0 FROM (select * from ks_radar_plus_public.radar_krn_dwd_load_stat WHERE p_date >= '20231122' AND p_date <= '20231128' limit 10000000) t GROUP BY __time__p_date, _0 ORDER BY __time__p_date, _0 LIMIT 200 OFFSET 0; ```
-
order by rand() LIMIT Z- 优点:采样均匀。适合小表(日增行数1E6)。
- 缺点:无法避免失败,性能较差。
``` -- LIMIT Y: 5s SELECT 1659369600000 AS __time__p_date, query_id AS _0 FROM (SELECT * FROM ks_kwaibi.kwaibi_query_metric_cost_detail_daily WHERE p_date >= '20220802' AND p_date <= '20220809' AND LOWER(query_id) LIKE LOWER('%kw%') LIMIT 10000000) GROUP BY __time__p_date, _0 ORDER BY __time__p_date, _0 LIMIT 200 OFFSET 0 ; -- ORDER BY RAND() LIMIT Z: 5s SELECT 1659369600000 AS __time__p_date, query_id AS _0 FROM (SELECT * FROM ks_kwaibi.kwaibi_query_metric_cost_detail_daily WHERE p_date >= '20220802' AND p_date <= '20220809' AND LOWER(query_id) LIKE LOWER('%kw%') ORDER BY RAND() LIMIT 100000) GROUP BY __time__p_date, _0 ORDER BY __time__p_date, _0 LIMIT 200 OFFSET 0 ; ```
Global Join
- 查询放大
- 在各shard所在的node分别执行一次t2子查询,查询计算复杂度 x k.
- 用于分布式JOIN distributed_engine_1 A JOIN distributed_engine_2 B,查询计算复杂度 k x k.
- 优化手段
- 在某node执行该子查询 s2 1次,然后网络传输给其他node. 减少查询次数, 类似 Broadcast JOIN in Spark.
- 近似的,如果A,B shard都为k,则 O(k x k) -> O(k + k)
- syntax
t1 GLOBAL JOIN t2t1 where c1 GLOBAL IN t2- t2可能是子查询
- 实践: 单node计算完成后发送的数据结果造成网络IO压力过大,t2小维表大约200w行数据(底表记录数)。
Local Query
- 在同server节点执行分片计算,然后在coordinator简单汇总
- 单表:稳定 sharding by k1, 查询模式
count(distinct k1). 依然有 coordinatorsum(cnt_i). 可避免 coordinator 去重计算时发生内存瓶颈。 -
多表关联:fact, dim 都使用相同的稳定 sharding key, 然后可在同节点 JOIN 后,执行类似单表的 Local Query.
- k shards,数据量M,N,有 1/k 的收益。O(M x N) -> O(M/k x N/k * k) = O(M x N / k)
- 同时优化CPU及I/O复杂度 1/k.
-
syntax
``` localQuery(cluster, main table, local query) cluster:clickhouse集群,即local表所在的集群 main table:分布式表对应的local表,对应的replica merge tree可能会有lag,按这个来选择查询的replica local query:查询本地的数据,所有的表都需要指定local表 ``` -
demo
``` select p_date ,p_product ,sum(sum1) as sum1 ,sum(sum2) as sum2 ,sum(sum3) as sum3 FROM localQuery( app_hdd, ks_growth.ck__device__channel_active_device__di_local, " select p_date ,p_product ,sum(antispam_active_device_cnt) as sum1 ,sum(new_device_cnt) as sum2 ,sum(antispam_new_device_cnt) as sum3 from ks_growth.ck__device__channel_active_device__di_local where p_date >= '20201101' and p_date <= '20201104' group by p_date, p_product limit 1000000 " ) group by p_date, p_product order by p_date, p_product, sum1 limit 1000000 ```
案例
XTD
时间累计函数,例如计算“近x小时累计”,“0点截止到当前”,“近x日累计”,“月初截至当日”等可累加指标。
-
over()function for Expr & Aggr-
syntax
``` -- CH aggregate_function (column_name) OVER ([[PARTITION BY grouping_column] [ORDER BY sorting_column] [ROWS or RANGE expression_to_bound_rows_withing_the_group]] | [window_name]) FROM table_name WINDOW window_name as ([[PARTITION BY grouping_column] [ORDER BY sorting_column]) -- 开窗 e.g., acc(m1) over([partition by window_size] order by p_date window_frame) from subquery -- subquery 为时间聚合粒度下的分组,普通聚合结果 -- e.g., select dt, dims, sum(m1) as m1 from t where dt >= biggest_granu_start AND dt <= end group by dt, dims; ``` -
demo
``` select t.* -- 累积求和 ,sum(normal_sum) over(partition by g_day order by g_hour asc ROWS between unbounded preceding and current row ) as run_tot from ( WITH cte AS (SELECT 0 as t, 1 as v, 1 AS d -- (g_day, g_hour) = (0, 0) UNION ALL SELECT 1, 1, 1 -- (g_day, g_hour) = (0, 0) UNION ALL SELECT 1, 1, 0 -- (g_day, g_hour) = (0, 0) UNION ALL SELECT 2, 1, 1 -- (g_day, g_hour) = (0, 1) UNION ALL SELECT 3, 2, 1 -- (g_day, g_hour) = (0, 1) UNION ALL SELECT 4, 4, 1 -- (g_day, g_hour) = (0, 2) UNION ALL SELECT 5, 4, 1 -- (g_day, g_hour) = (0, 2) UNION ALL SELECT 6, 6, 1 -- (g_day, g_hour) = (1, 3) UNION ALL SELECT 7, 7, 0 -- (g_day, g_hour) = (1, 3) UNION ALL SELECT 8, null, 1 -- (g_day, g_hour) = (1, 4) ) select floor(t/6) as g_day, floor(t/2) as g_hour, -- 普通求和指标 sum(v) as normal_sum, from cte group by g_hour, g_day ) t order by g_day, g_hour ; ```
-
-
嵌套模板编排
- 筛选时间范围对齐
[start, end] => [biggest_granu_start, end], biggest_granu_start <= start - AccBaseTmpl 子查询,外层查询利用开窗函数 + 子查询计算累计指标,同时出普通指标.
- class diagram

- control flow
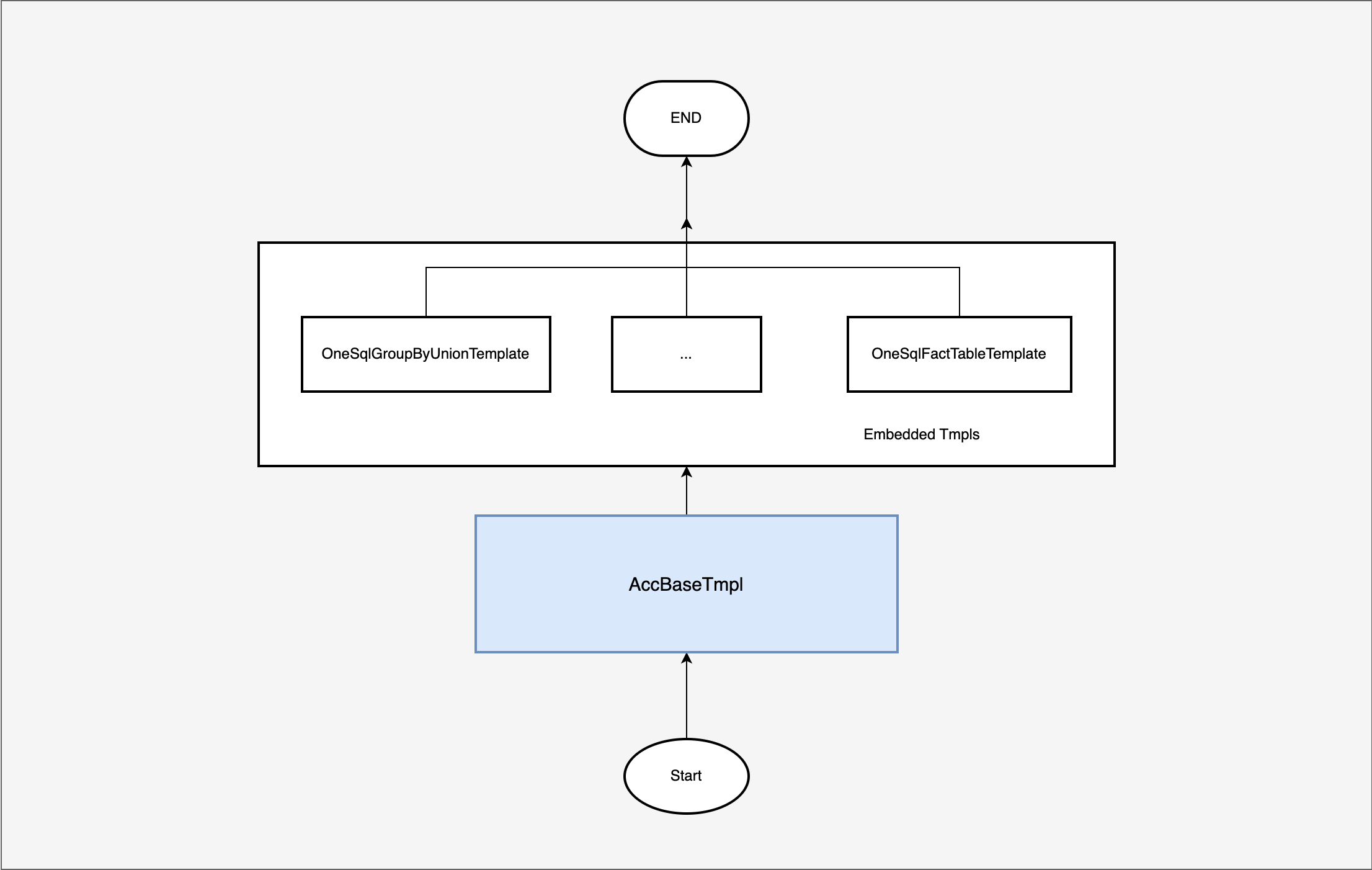
- class diagram
- 修正筛选时间范围, 按原筛选时间过滤 [start, end]
select * from res where dt >= start AND dt <= end
- 筛选时间范围对齐
-
累计计算实现方式对比
- runningAccmulate()
- runAcc() 不建议去重计数的累计,否则底层状态保存代价很大 (uniqState)
- 不支持近x日: sliding window (window frame)
- over()
- 相对底表有时间聚合粒度时,不支持去重计数的累计
- 都是基于子查询,外层出累计指标
- 子查询中计算普通求和指标,外层累计时,同时输出普通指标。
- 支持 sum() aka. running_total , avg() aka. moving average, rank()
- runningAccmulate()
性能治理
- 看板加速:BI层级缓存/预刷/预热
- Adhoc慢查询感知:查询过程白盒化
- 诊断加速: 生产/分析
- 精确去重高基数列,优化建议:使用近似去重计算函数替换精确去重函数
- 存在非全量表的大维表关联,优化建议:生产宽表
- 扫描数据量过大,优化建议:生产小表
- 降本增效
- 流量规范化: 定位什么用户在什么场景查询了什么表
- 流量认证开启策略
- 免认证白名单:观察已知流量,全集添加到白名单,开启认证,逐个减少到0,拦截到非法流量时告警。
- 申请被认证的名单:没有人愿意主动被限制,可以预想用户不配合,推进难度大。从0增加直到开启认证拦截,期间非法流量可能长期存在。
- 流量认证开启策略
- 分级限流: 应用层传递相对优先级,BI层统筹确定各应用层相对优先级,确定一次查询的优先级,引擎层根据优先级可分级限流
- 流量规范化: 定位什么用户在什么场景查询了什么表
Inspiration
ML
- 回归。StochasticLinearRegression.
- 分类。StochasticLogisticRegression.
- fitting: 理解为聚合函数,输入为一张表,输出为参数表。
- predicting: 输入为参数表和测试数据表,输出为预测值. evalMLMethod(ML_method, test_data_table.col1, test_data_table.col2)
- 或者一步到位,同时输出模型参数和训练预测值:select ML_method(config)(target, col1, col2) from train_data;
成本因素
- 集群规模: 核数,内存与磁盘。
- SSD.
- 复杂query
- 引擎种类
- 副本
- 分片
- 扩容: 运维Zookeeper。
- 数据量。
- 业务SQL实测benchmark.
存储计算分离
- 目标
- 数据可存放在remote, 当计算节点需要数据时,从remote做即席获取,再计算
- 好处
- 可以做冷热数据分离,冷数据用低廉存储系统持久化,加载到本地进行计算。
- 增加较少成本,存储更多数据,不损失性能。
- 可配合自动伸缩,动态调节计算集群规模。
- 现状
- 适用于离线数仓加速,而非实时OLAP。
- 已经支持S3作为扩展存储,但是需要做数据COPY。
- 社区2021主要目标:完全的存储计算分离。2024大厂未落地。
- 实验
- Huawei Cloud: 5x delay; 10x cost saving.
- JuiceFS: 少量cost,增加几倍容量,几乎不损失性能。
SQL SCCS OLAP BI